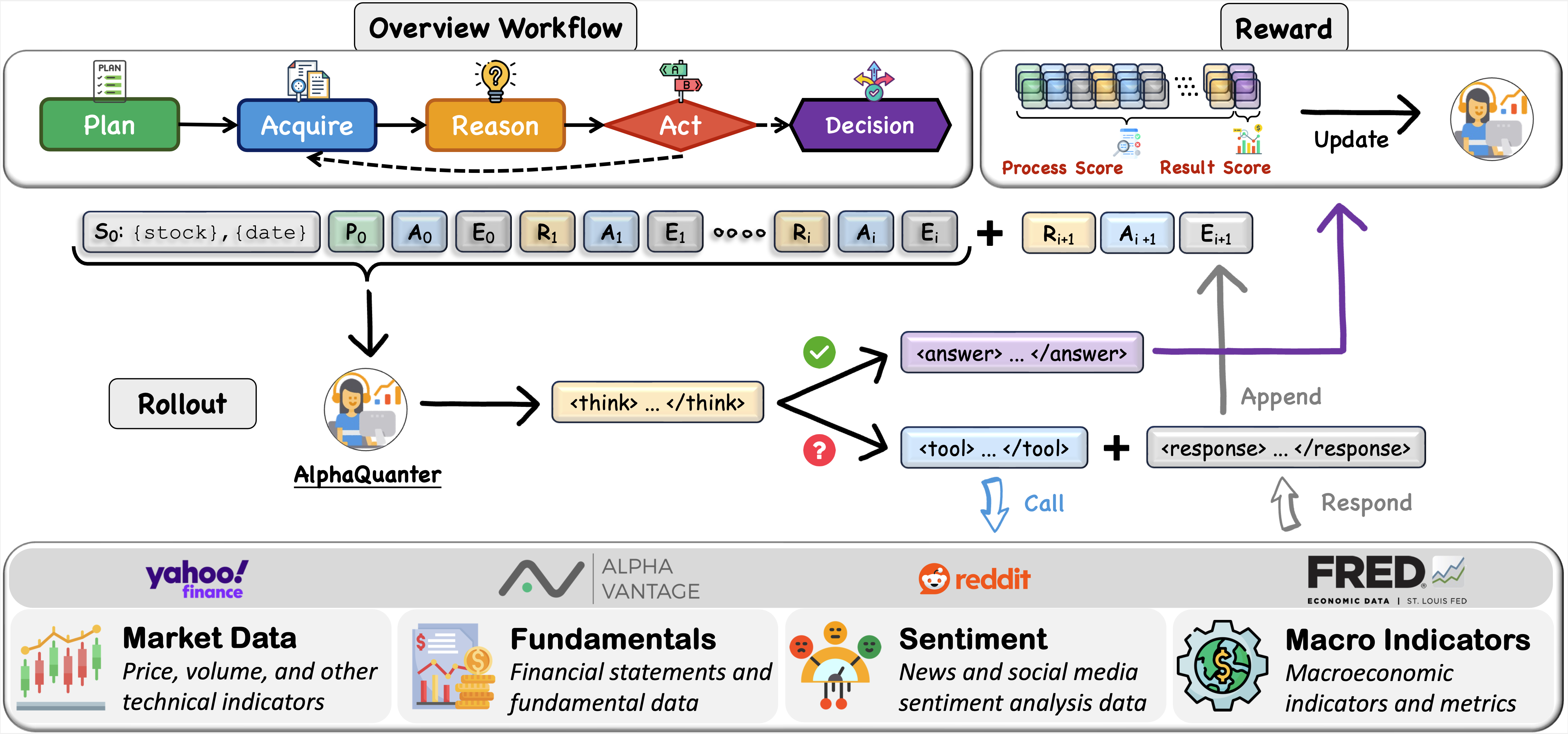
 Overall Workflow of AlphaQuanter
Overall Workflow of AlphaQuanter
 Abstract
Abstract
While Large Language Model (LLM) agents show promise in automated trading, they still face critical limitations. Prominent multi-agent frameworks often suffer from inefficiency, produce inconsistent signals, and lack the end-to-end optimization required to learn a coherent strategy from market feedback. To address this, we introduce AlphaQuanter, a single-agent framework that uses reinforcement learning (RL) to learn a dynamic policy over a transparent, tool-augmented decision workflow, which empowers a single agent to autonomously orchestrate tools and proactively acquire information on demand, establishing a transparent and auditable reasoning process. Extensive experiments demonstrate that AlphaQuanter achieves state-of-the-art performance on key financial metrics. Moreover, its interpretable reasoning reveals sophisticated strategies, offering novel and valuable insights for human traders.
 Evaluation Results on 5 Stocks
Evaluation Results on 5 Stocks
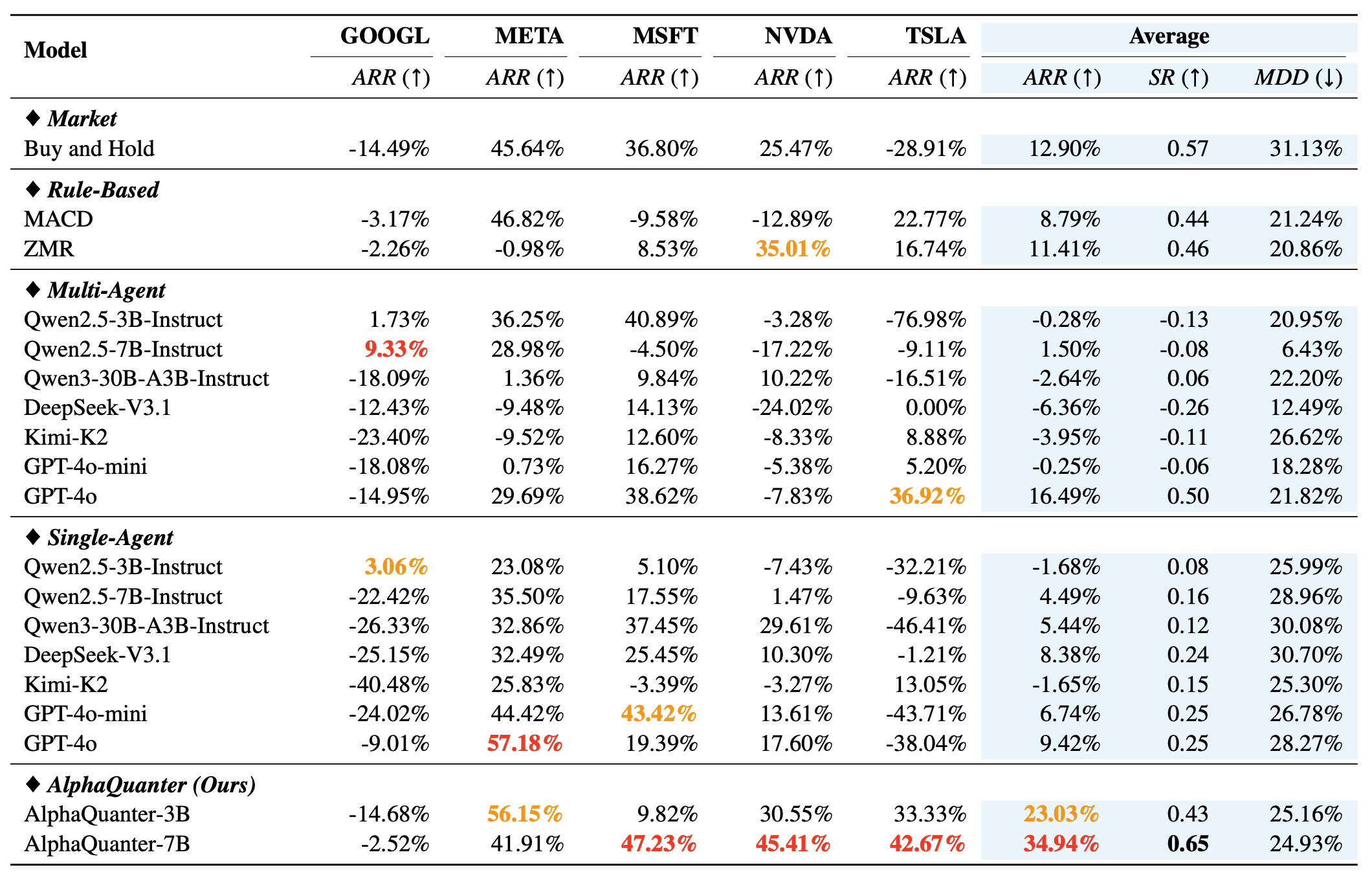
Key Observations
- A single-agent framework is generally superior to a multi-agent one.
- Prompt-based reasoning alone is insufficient for trading.
- Our proposed AlphaQuanter, optimized with end-to-end reinforcement learning, significantly outperforms all baselines.
 Training Dynamics & Validation Performance
Training Dynamics & Validation Performance
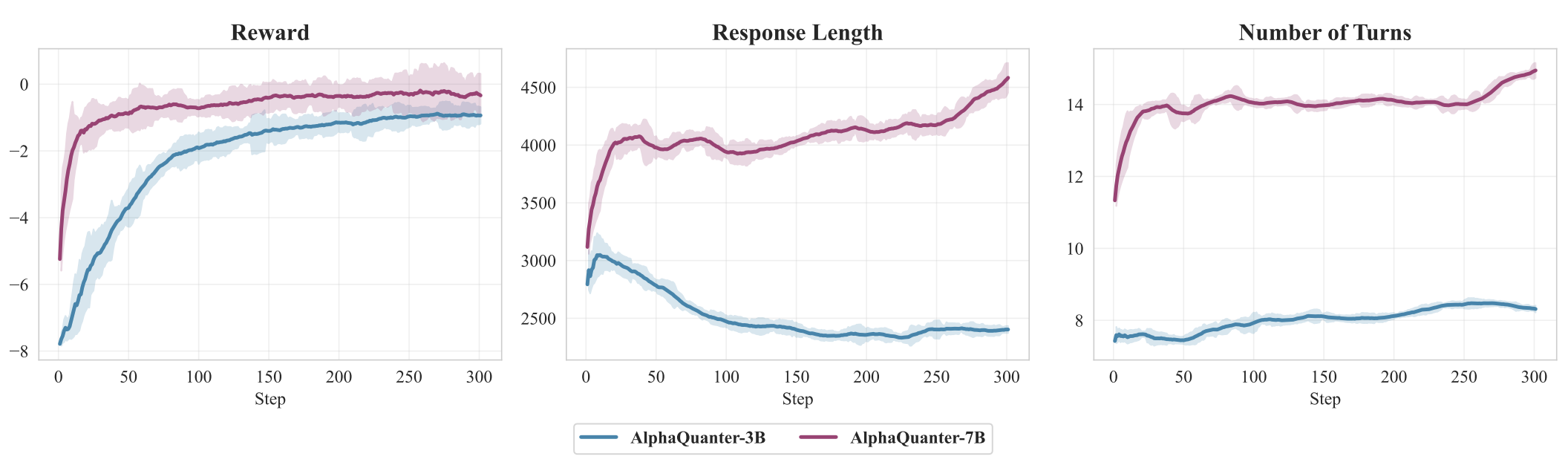
The training dynamics reveal that while both models learn, the 7B model enters a sophisticated policy refinement phase, whereas the 3B model converges prematurely to a simplistic strategy.
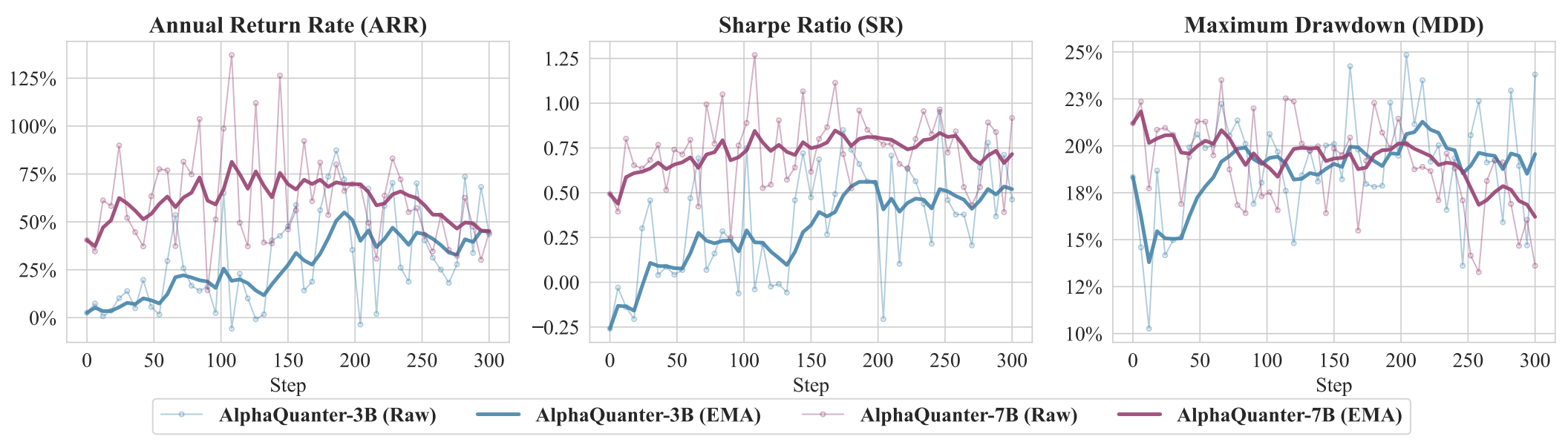
Validation performance confirms the 7B model's superior generalization, as it not only improves returns but also learns to effectively manage downside risk (decreasing MDD), a crucial capability the 3B model fails to acquire.
 Tool Usage Patterns
Tool Usage Patterns
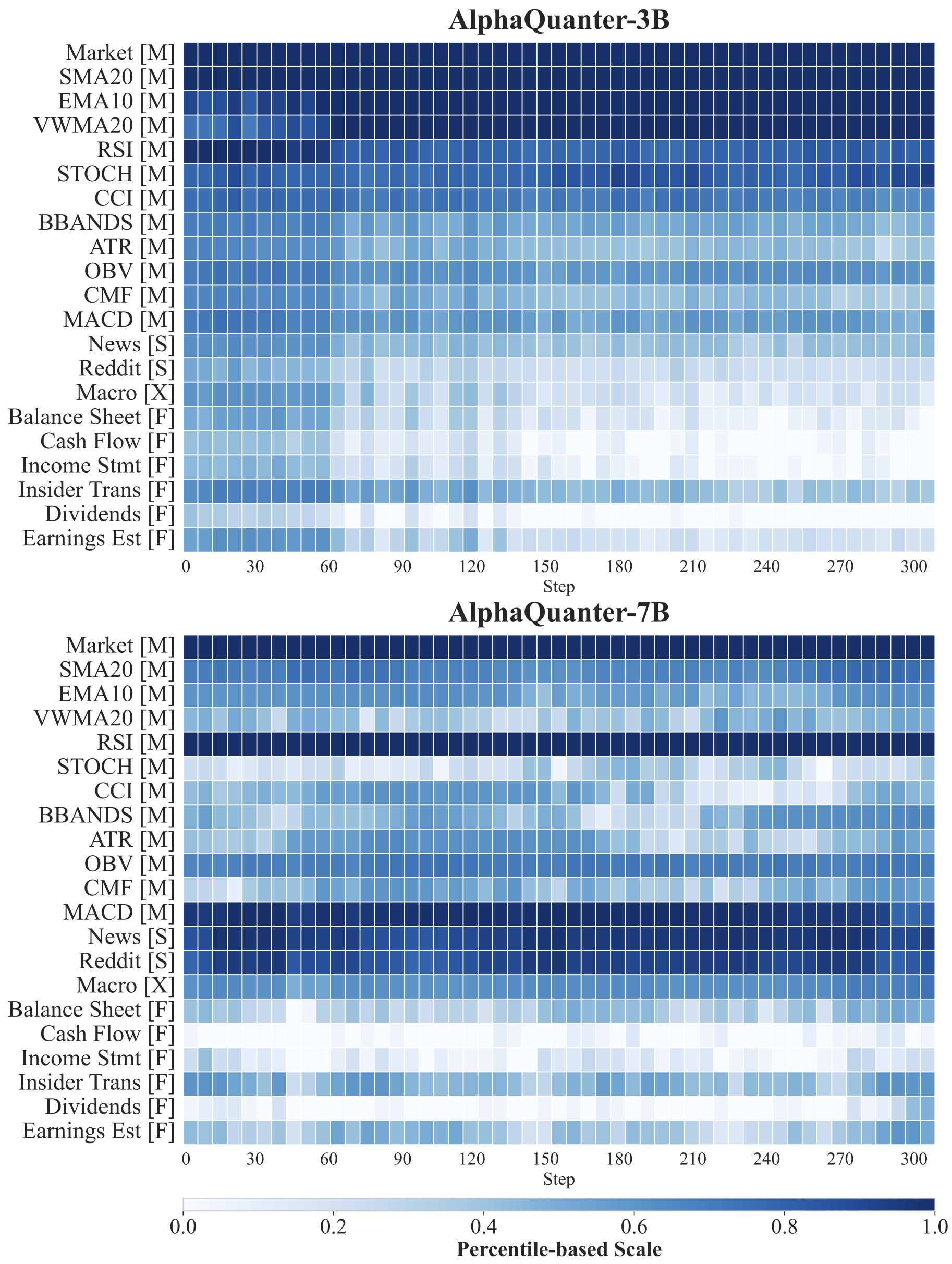
Evolution of tool-selection strategies for AlphaQuanter-3B and -7B during training, where heatmap intensity indicates percentile-based reliance on four data sources ([M], [S], [X], [F]).
Key Observations
- Agents actively learn and refine their information-seeking policies, proving their strategies are dynamic, not static.
- The 7B model develops a focused and selective strategy, while the 3B model’s approach is more diffuse and less discerning.
- The 7B model discovers a sophisticated, expert-like heuristic, prioritizing key technical indicators (like trend and volume) and using sentiment or macro data as secondary signals.
 Ablation Study
Ablation Study
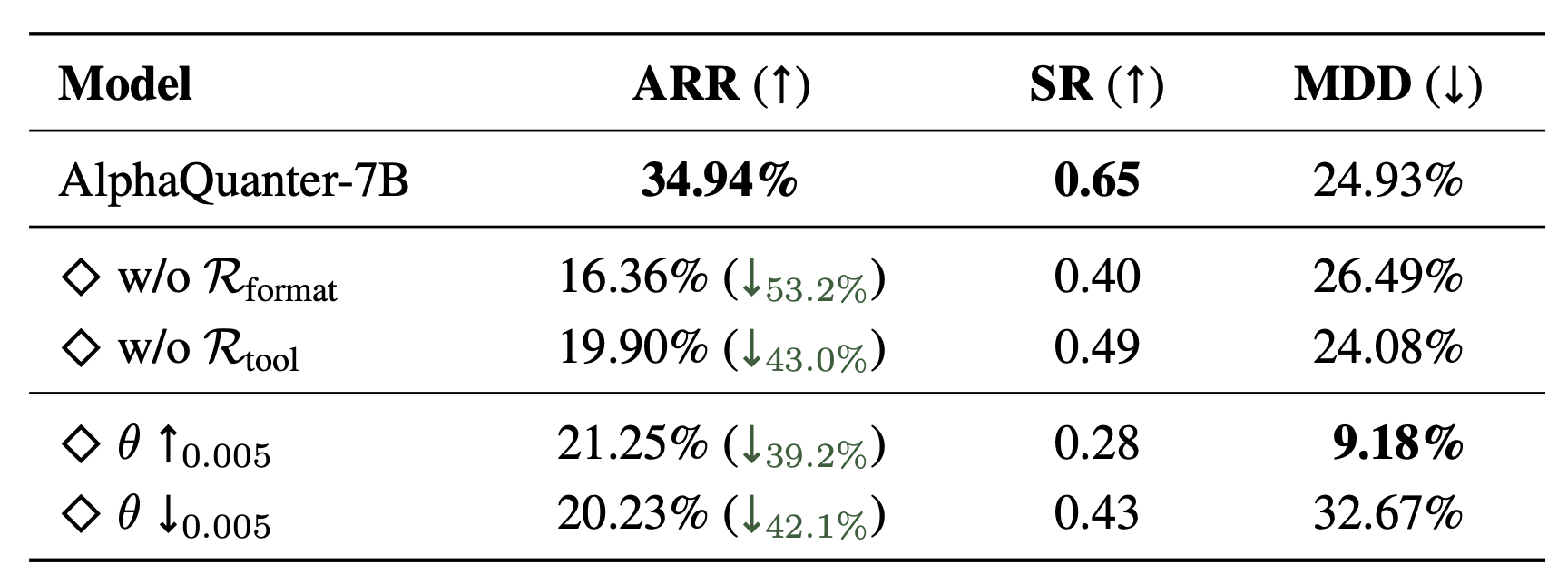
Our ablation study validates the critical contribution of our reward components and the high sensitivity of the decision threshold (θ) to the agent's overall performance and strategic behavior.
BibTeX
@misc{deng2025alphaquanterendtoendtoolorchestratedagentic,
title={AlphaQuanter: An End-to-End Tool-Orchestrated Agentic Reinforcement Learning Framework for Stock Trading},
author={Zheye Deng and Jiashu Wang},
year={2025},
eprint={2510.14264},
archivePrefix={arXiv},
primaryClass={cs.CE},
url={https://arxiv.org/abs/2510.14264},
}